Hogfather,
мне тоже эта тема интересна. Но я полный ноль. Разбираюсь.
Цитата:
Сообщение от Hogfather
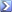
Из набора данных выделяем непересекающиеся данные для тренировки модели (train set), валидации (validation set) и тестирующие данные (test set). Самый большой блок из этого - train set. Validation set и test set примерно равны.
|
Вот здесь вопрос. Я обычно в статьях (финансовые модели) читаю разделение на 2 множества: calibration sample and validation sample (часть данных, на которых оцениваем параметры и часть данных, на которых потом проверяем модель).
Добавлено через 2 минуты
А можно я еще спрошу.. в МатЛабе, например, оцениваем GARCH модели. Там такая табличка с полученными оценками и последний столбец - t Statistic. Вот здесь, например
http://www.mathworks.com/help/econ/f...e-returns.html
Подскажите, пожалуйста, что это значит (столбец
t Statistic). Или где можно почитать.