Цитата:
Сообщение от Bronepoezd
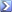
Результат запуска в R ниже
|
В общем, проблема в следующем. Я делал под MacOS, там локаль стоит UTF-8 и все работает. Windows не даёт сменить локаль, и теряет буквы ч. Изначально у меня терял и Мак, но шаманскими заклинаниями я заставил его корректно прочитать файл. Чтобы работало под Windows загрузку делаем вот так
Код:
dissers<-read.csv2("dissers.csv",header=T)
Тогда корректно закачиваются все данные в R. А дальше глючат две вещи:
Код:
xkcd.corpus <- tm_map(xkcd.corpus, removePunctuation)
тут в регулярном выражении должны были удалиться знаки препинания, но заодно удаляются буквы "ч" и "я". Что побеждается перекодировкой в UTF-8.
И, что самое страшное, глючит вот эта команда
Код:
tdm <- TermDocumentMatrix(xkcd.corpus)
Добавлено через 11 минут
Цитата:
Сообщение от Bronepoezd
Работает скрипт порядка 5 минут -- так и должно быть?
|
По 08 специальности да. Там много документов.
Добавлено через 3 часа 36 минут
Итак, только в нашем цирке:
TermDocumentMatrix который работает под Windows. В данном примере анализируются диссертации по двум специальностям 05.02.22 и 05.02.23, строится общее облако из всех терминов (объединение), а также анализируется, какой термин где что больше используется, а также пересечение терминов.
Код:
library(tm)
library(wordcloud)
library(RColorBrewer)
library(SnowballC)
dissers<-read.csv2("dissers.csv",header=T) # Данные читаем
strsplit_space_tokenizer <- function(x) unlist(strsplit(x, "[[:space:]]+"))
x1<-enc2utf8(tolower(paste(as.vector(subset(dissers,Nspec=="05.02.22")$diser),collapse = " ")))
x2<-enc2utf8(tolower(paste(as.vector(subset(dissers,Nspec=="05.02.23")$diser),collapse = " ")))
docs <- data.frame(docs = c(x1,x2),
row.names = c("05.02.22", "05.02.23"))
ds <- DataframeSource(docs,encoding ="UTF8")
ds.corpus <- Corpus(ds,readerControl = list(reader = readPlain, language = "ru"))
ds.corpus <- tm_map(ds.corpus, removePunctuation)
ds.corpus<- tm_map(ds.corpus, removeWords,stopwords("russian"))
ds.corpus <- tm_map(ds.corpus, stemDocument,language = "russian")
ds.corpus <- tm_map(ds.corpus, stripWhitespace)
#ds.corpus <- tm_map(ds.corpus, tolower)
tdm <- TermDocumentMatrix(ds.corpus,control = list(tokenize=strsplit_space_tokenizer))
m <- as.matrix(tdm)
v <- sort(rowSums(m),decreasing=TRUE)
d <- data.frame(word = names(v),freq=v)
pal <- brewer.pal(9, "BuGn")
pal <- pal[-(1:2)]
pal2 <- brewer.pal(8,"Dark2")
## Рисунок 1
png("wordcloud1.png", width=600,height=600)
wordcloud(d$word,d$freq, scale=c(6,.2),min.freq=5,
max.words=Inf, random.order=FALSE, rot.per=.15, colors=pal2)
dev.off()
## Рисунок 2
png("wordcloud2.png", width=600,height=600)
comparison.cloud(m, colors = pal2, title.size=2, max.words=500)
dev.off()
## Рисунок 3
png("wordcloud3.png", width=500,height=500)
commonality.cloud(m, colors = pal2, max.words=500)
dev.off()
Добавлено через 18 минут
Код:
# Дендрограмма
# оставляем только самы частые слова (9 дециль)
wf = rowSums(m)
m1 = m[wf>quantile(wf,probs=0.9), ]
# удаляем пустые колонки
m1 = m1[,colSums(m1)!=0]
# преобразуем в двоичный вид
m1[m1 > 1] = 1
# матрица двоичных дистанций
m1dist = dist(m1, method="binary")
# кластер с использованием объединения по методу Варда
clus1 = hclust(m1dist, method="ward")
# дендрограмка
plot(clus1, cex=0.7)
 Добавлено через 32 минуты
Добавлено через 32 минуты
Своды документов можно объединять командой c()
Код:
# Расширяем нашу коллекцию
x3<-enc2utf8(tolower(paste(as.vector(subset(dissers,Nspec=="08.00.05")$diser),collapse = " ")))
docs <- data.frame(docs = x3,
row.names = "08.00.05")
ds1 <- DataframeSource(docs,encoding ="UTF8")
ds1.corpus <- Corpus(ds1,readerControl = list(reader = readPlain, language = "ru"))
ds1.corpus <- tm_map(ds1.corpus, removePunctuation)
ds1.corpus<- tm_map(ds1.corpus, removeWords,stopwords("russian"))
ds1.corpus <- tm_map(ds1.corpus, stemDocument,language = "russian")
ds1.corpus <- tm_map(ds1.corpus, stripWhitespace)
tdm <- TermDocumentMatrix(c(ds.corpus,ds1.corpus),control = list(tokenize=strsplit_space_tokenizer))
## Рисунок 4
m <- as.matrix(tdm)
png("wordcloud4.png", width=1000,height=1000)
comparison.cloud(m, colors = pal2, title.size=2, max.words=500)
dev.off()
Добавлено через 6 часов 56 минут
Поскольку просто так потратить кучу времени на изучение пакета было бы обидно, пишу статью в нашу вузовскую "Мурзилку" по мотивам анализа данных. Коню понятно, что "играть" на форуме -- это одно, а более-менее серьезное исследование -- это другое, то возник вопрос, что делать с дубликатами защит. А они есть и искажают картину качественно и количественно. Так вот, в R все давно придумано до нас и не надо подключать никаких дополнительных пакетов. Есть чудесная команда
duplicated, которая возвращает логический вектор.
Вызов duplicated(dissers[,c(1,3,5)], fromLast = TRUE) проверяет наличие строк, в которых дублированы специальность, вид защиты и фамилия. Логика следующая: дубликаты, в большинстве случаев, возникают когда переносят защиту или когда есть ошибка в названии АР. Обратите внимание: убрано 1185 дублирующихся записей. Теперь анализ проводить гораздо корректнее. Напоминаю, что команда dim выводит размер матрицы или таблицы данных (число строк, число столбцов). По сути, нужна только команда dissers<-dissers[!duplicated(dissers[,c(1,3,5)], fromLast = TRUE),]
Код:
> dim(dissers)
[1] 43522 6
> dissers<-dissers[!duplicated(dissers[,c(1,3,5)], fromLast = TRUE),]
> dim(dissers)
[1] 42337 6
Добавлено через 2 часа 36 минут
Трансформация данных и построение графика
Код:
library(reshape2)
md<-data.frame(spec=substr(dissers$Nspec,1,2),time=paste(substr(dissers$date,7,10),substr(dissers$date,4,5),sep="."),cnt=1)
res<-dcast(md,time~spec,sum,value.var="cnt")
row.names(res)<-res$time
res<-as.matrix(t(res[,-1]))
oldpar<-par(mai=c(1.36,1.09,1.09,1.56))
barplot(as.matrix(res)[,-1],col=rainbow(18),legend.text=rownames(res),las=2,args.legend=list(x=35),main="Динамика защит")
par(oldpar)
 Добавлено через 11 часов 17 минут
Добавлено через 11 часов 17 минут
Продолжаем издеваться над теми же данными. А вот пример диаграммы Венна. Очень меня интересуют слова-заглушки: инновации, оптимизация, механизм и т.п. Сказано -- сделано. Строим табличку совпаданий, а затем строим диаграмму.
Код:
library(gplots)
dis.df<-dissers # Тут может быть любая выборка
Test.df<-data.frame("Качество"=grepl("качеств",tolower(dis.df$diser)),
"Инновации"=grepl("инновац",tolower(dis.df$diser)),
"Оптимизация"=grepl("оптимизац",tolower(dis.df$diser)),
"Эффективность"=grepl("эффективн",tolower(dis.df$diser)),
"Механизм"=grepl("механизм",tolower(dis.df$diser)))
rm(dis.df)
venn(Test.df)

Радуемся "оптимизации эффективности качества" и т.п.
Добавлено через 13 часов 28 минут
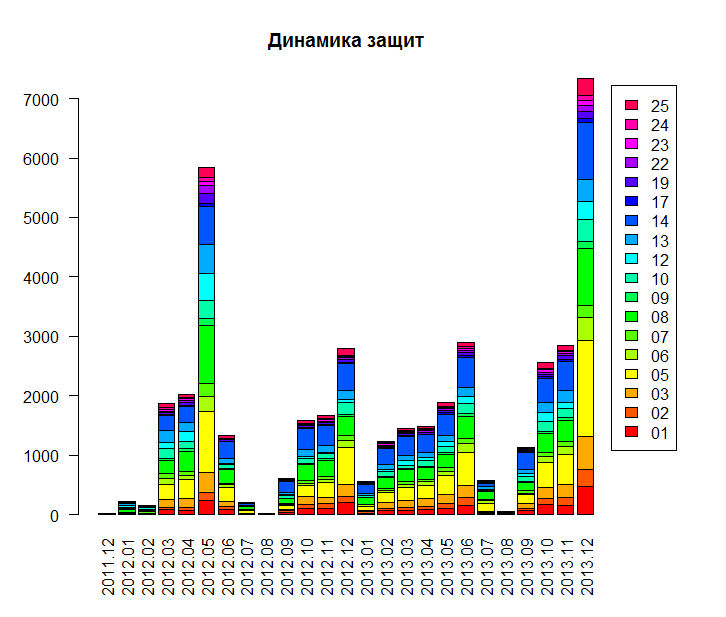
Следующий пример визуализации данных несколько из другой области. Чисто экономические заморочки -- бридж диаграмма, также называемая
waterfall chart. Так вот, в R есть и она. Диаграмма может быть полезна визуализации экономического эффекта с разбивкой по факторам. Можно строить в классическом виде, а можно как в журнале The Economist. Собственно, не растекаясь мысью по древу, код и картинки.
Код:
> library(waterfall)
> data(rasiel) # Пример данных, имеющихся в пакете
> rasiel
label value subtotal
1 Net Sales 150 EBIT
2 Expenses -170 EBIT
3 Interest 18 Net Income
4 Gains 10 Net Income
5 Taxes -2 Net Income
> waterfallchart(value~label, data=rasiel, groups=subtotal, main="P&L")
> asTheEconomist(waterfallchart(value~label, data=rasiel, groups=subtotal, main="P&L"))
Также можно воспользоваться пакетом ggplot2 и нарисовать графики с использованием его инструментов. Подробности можно посмотреть
вот тут.
Добавлено через 5 часов 47 минут
Еще немного визуализации нечисловых данных. Анализируем пропорции авторефератов на сайте ВАК по экономике.
Код:
library(reshape2)
library(vcd)
tmp<-subset(dissers,substr(Nspec,1,2)=="08")[,2:4]
tmp$date<-substr(tmp$date,7,10)
for(i in 1:3) tmp[,i]=factor(tmp[,i])
mosaic(~TypeOfDisser+Nspec+date, data=tmp,expected=~TypeOfDisser:Nspec + TypeOfDisser:date + Nspec:date,legend=FALSE, gp=shading_binary,pop=FALSE,
labeling_args=list(rot_labels=c(right=0),gp_labels=gpar(fontsize=8)))
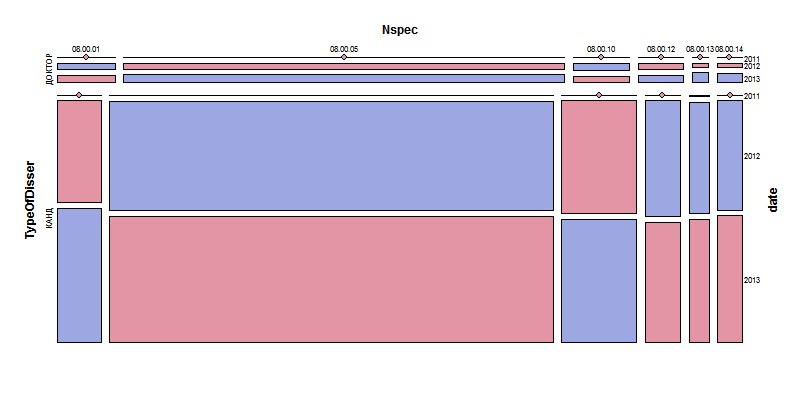
Возможности пакета vsd этим не исчепывается. Подробнее
в документации к пакету.