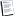 Алгоритм построения прогнозирующей модели (predictive model)
Алгоритм построения прогнозирующей модели (predictive model)
Некоторый поток сознания, чтобы разобраться.
Имеется некоторый набор количественных данных, от которых зависит качественный показатель (Хорошо, Плохо, Очень плохо и т.д.). Стоит задача построить прогнозирующую модель и проверить её на тестовых данных.
Алгоритм вырисовывается следующий.
1. Из набора данных выделяем непересекающиеся данные для тренировки модели (train set), валидации (validation set) и тестирующие данные (test set). Самый большой блок из этого - train set. Validation set и test set примерно равны.
2. Строим пару-тройку приличных моделей, например, случайный решающий лес (Random Forest) и модель на базе опорных векторов (SVM) на тренировочных данных. На них же настраиваем модели.
3) Модели натравливаем на данные для валидации и выбираем одну модель, дающую меньше всего ошибок.
4) Проверяем выжившую аки Горец модель на тестовых данных. Строим матрицу неточностей (confusion matrix), графики, диаграммы и прочую ерунду.
....
N) PROFIT!
Замечания, предложения?
|