Хотя меня особо не спрашивают, но
имея опыт работы со студентами постараюсь кратко и без лишнего занудства изложить, что же Пытливый Ум может увидеть в сборище букв на языке эвентуального противника, когда строит модель.
Рассмотрим пример, который был приведен выше.
Код:
> summary(fit)
Call:
lm(formula = lnZ ~ x + y, data = myData)
Residuals:
Min 1Q Median 3Q Max
-0.61700 -0.30351 -0.03218 0.19850 0.81873
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.5939071 0.3067107 -1.936 0.0678 .
x 0.0016541 0.0012529 1.320 0.2025
y 0.0029021 0.0002526 11.488 5.4e-10 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.4538 on 19 degrees of freedom
Multiple R-squared: 0.889, Adjusted R-squared: 0.8773
F-statistic: 76.08 on 2 and 19 DF, p-value: 8.53e-10
Итак, первое на что мы смотрим, это не на разные Эр квадрат и прочие коэффициенты, нас интересует только вот эта строчка:
F-statistic: 76.08 on 2 and 19 DF, p-value: 8.53e-10
В данном случае нулевая гипотеза выглядит так: H
0: β
1=β
2=...β
n=0, т.е. все коэффициенты кроме свободного члена равны 0.
Это мы проводим проверку
значимости модели. Если p-value у нас превышает 0.05, то дальнейшая работа с моделью просто бессмысленна, поскольку модель незначимая.
Пример незначимой модели
Код:
> lm0<-lm(y~x,data=test)
> summary(lm0)
Call:
lm(formula = y ~ x, data = test)
Residuals:
Min 1Q Median 3Q Max
-3.3245 -1.4632 0.6214 1.3782 2.6417
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.4424 0.8937 3.852 0.00117 **
x 0.1102 0.0746 1.478 0.15681
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.924 on 18 degrees of freedom
Multiple R-squared: 0.1082, Adjusted R-squared: 0.05862
F-statistic: 2.183 on 1 and 18 DF, p-value: 0.1568
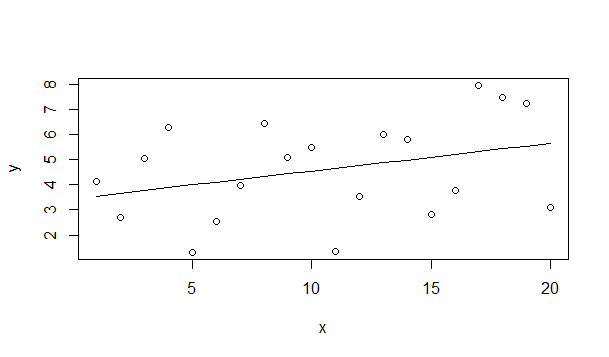
Второе, на что мы смотрим, это на остатки модели (Residuals).
Код:
Residuals:
Min 1Q Median 3Q Max
-0.61700 -0.30351 -0.03218 0.19850 0.81873
Алгоритм МНК подразумевает, что матожидание остатков должно быть равно 0 и мы надеемся, что остатки имеют нормальное распределение. Напоминаю, что у нормального распределения матожидание и медиана совпадают. В данном случае -- не очень. Поскольку мы видим отрицательную медиану (-0.03218), то распределение остатков незначительно смещено влево. Квартили, по идее, должны быть симметричны относительно 0, здесь же они значительно смещены влево. Максимум и минимум позволяют оценить
выбросы (outliers) модели.
Третье, на что мы смотрим -- коэффициенты.
Код:
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.5939071 0.3067107 -1.936 0.0678 .
x 0.0016541 0.0012529 1.320 0.2025
y 0.0029021 0.0002526 11.488 5.4e-10 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Для каждого коэффициента регрессора мы проверяем его значимость, вычисляя соответствующую t-статистику и проверяя нулевую гипотезу о незначимости его коэффициента. В дальнейшем мы будем по очереди убирать регрессоры исходя из наибольшего значения в последней колонке. Впрочем, об этом уже писалось.
Дальше,
Residual standard error: 1.924 on 18 degrees of freedom говорит нам о средней квадратической ошибке остатков (σ).
Multiple R-squared: 0.889, Adjusted R-squared: 0.8773 говорит о коэффициентах детерминации и
качестве модели. Чем они ближе к единице, тем лучше.
В то же время, проверку
адекватности модели следует произвести графически. Именно для этого все графики и строились..
Пример неадекватной модели
Код:
> test<-data.frame(x<-1:20)
> test$y<-sqrt(test$x)
> lm0<-lm(y~x,data=test)
> summary(lm0)
Call:
lm(formula = y ~ x, data = test)
Residuals:
Min 1Q Median 3Q Max
-0.46467 -0.08467 0.04310 0.13672 0.17227
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.294290 0.081968 15.79 5.44e-12 ***
x 0.170382 0.006843 24.90 2.13e-15 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.1765 on 18 degrees of freedom
Multiple R-squared: 0.9718, Adjusted R-squared: 0.9702
F-statistic: 620 on 1 and 18 DF, p-value: 2.127e-15
Обратите внимание на R
2
А теперь смотрите на график
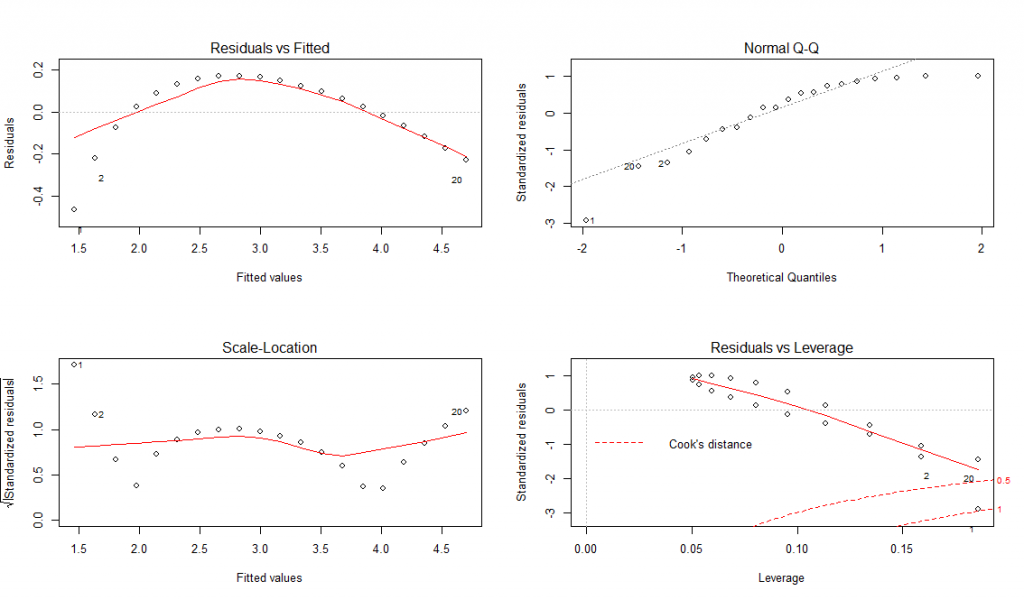
Что должно быть на графике:
1. Точки на графике Residuals vs Fitted должны быть случайно разбросаны, без явно выраженного тренда. Тут этого нет.
2. Точки на графике Normal Q-Q должны более-менее лежать на линии, показывая что остатки имеют нормальное распредение
3. Точки на двух остальных графиках должны быть в группах не слишком далеко от центра.
Т.е. модель у нас неадекватна, не смотря на милый Эр Квадрат. Такие дела.
Для сравнения
посмотрите график на предыдущей странице
Добавлено через 4 часа 3 минуты
Использование метода Бокса-Кокса для преобразования регрессионной модели
В предыдущем примере мы рассмотрели случай, когда модель выбрана неадекватной. Судя по параболе, которую мы наблюдаем, здесь необходимо какое-то степенное преобразование.
Попробуем использовать преобразование Бокса-Кокса, которое входит в пакет MASS. Т.е. найдем такую λ, чтобы y
λ сделал нам аж боже мой.
Исходные данные у нас те же и та же модель.
Код:
> test<-data.frame(x<-1:20)
> test$y<-sqrt(test$x)
> lm0<-lm(y~x,data=test)
А дальше начинается колдунство. В данном случае lambda взята в интервале 0 до 4 с шагом 0.01 ( по умолчанию -2 до 2 с шагом 0.1)
Код:
> library(MASS)
> bc<-boxcox(lm0,lambda = seq(0,4,0.01))
Получаем следующий график зависимости логарифмической функции правдоподобия от лямбды.
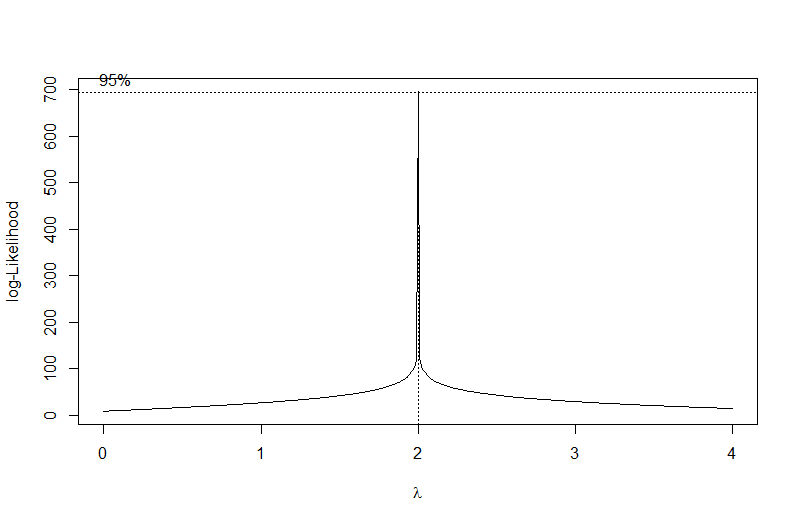
К сожалению, конкретного результата, который нужно подставить у нас нигде нет. Но мы можем его получить. Функция which.max(bc$y) вернёт нам номер элемента, у которого Игрек наибольший, а bc$x[which.max(bc$y)]) -- собственно нужную лямбду.
Код:
> (lambda<-bc$x[which.max(bc$y)])
[1] 2
Лямбда получилась равной 2. Ах, удивительно!
Делаем преобразование и строим новую модель.
Код:
> lm1<-lm(I(y^lambda)~x,data=test)
> summary(lm1)
Call:
lm(formula = I(y^lambda) ~ x, data = test)
Residuals:
Min 1Q Median 3Q Max
-7.049e-15 -1.023e-15 -1.436e-16 1.235e-15 7.585e-15
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.000e+00 1.324e-15 0.000e+00 1
x 1.000e+00 1.105e-16 9.047e+15 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.85e-15 on 18 degrees of freedom
Multiple R-squared: 1, Adjusted R-squared: 1
F-statistic: 8.185e+31 on 1 and 18 DF, p-value: < 2.2e-16
Нарисуем первый график из четырех диагностических графиков модели.
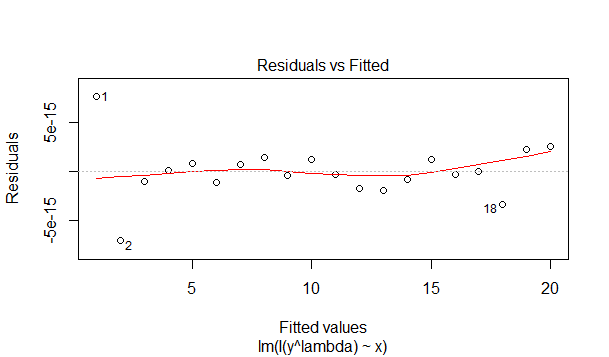
Воот! Теперь совсем другое дело.
Следует отметить особые случаи в преобразовании Бокса-Кокса. Если λ=1, то преобразование не требуется. Если λ=0, то следует использовать логарифмическое преобразование log(y). Пример.
Код:
> test<-data.frame(x<-1:20)
> test$y<-exp(-test$x)
> lm0<-lm(y~x,data=test)
> summary(lm0)
Call:
lm(formula = y ~ x, data = test)
Residuals:
Min 1Q Median 3Q Max
-0.06529 -0.04258 -0.01349 0.02358 0.26464
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.111047 0.034464 3.222 0.00473 **
x -0.007805 0.002877 -2.713 0.01426 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.07419 on 18 degrees of freedom
Multiple R-squared: 0.2902, Adjusted R-squared: 0.2508
F-statistic: 7.359 on 1 and 18 DF, p-value: 0.01426
> bc<-boxcox(lm0,lambda = seq(-4,4,0.01))
> (lambda<-bc$x[which.max(bc$y)])
[1] 0
> lm1<-lm(log(y)~x,data=test)
> summary(lm1)
Call:
lm(formula = log(y) ~ x, data = test)
Residuals:
Min 1Q Median 3Q Max
-2.038e-15 -6.074e-16 -3.526e-16 -8.400e-18 6.208e-15
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.766e-15 7.696e-16 6.193e+00 7.6e-06 ***
x -1.000e+00 6.425e-17 -1.557e+16 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.657e-15 on 18 degrees of freedom
Multiple R-squared: 1, Adjusted R-squared: 1
F-statistic: 2.423e+32 on 1 and 18 DF, p-value: < 2.2e-16
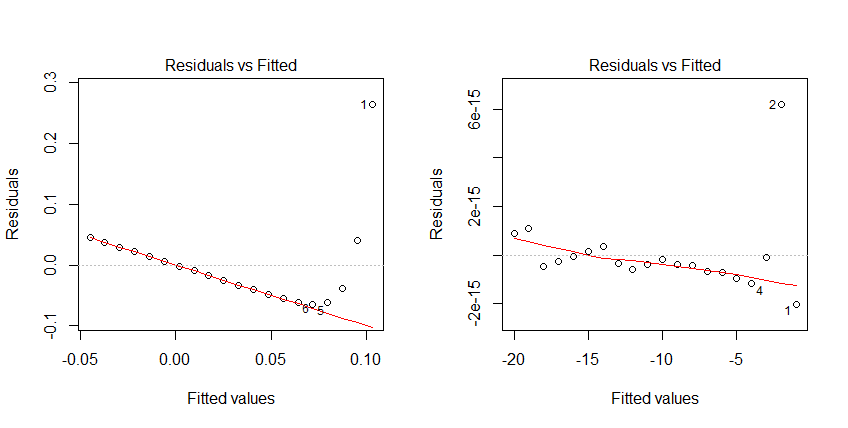
И для закрепления материала два графика. Слева -- плохой, негодный, а справа -- хороший, годный.
Скрипт для графика
Код:
> par(mfrow=c(1,2))
> plot(lm0,which=1)
> plot(lm1,which=1)
> par(mfrow=c(1,1))
 Добавлено через 18 часов 12 минут
Добавлено через 18 часов 12 минут
Кореллограммы
В рассмотренной задаче (
#10) рисовалась корреляционная матрица в виде соответствующих диаграмм рассеяния. Также можно получить корреляционную матрицу в виде коэффициентов корреляции в текстовом виде.
Код:
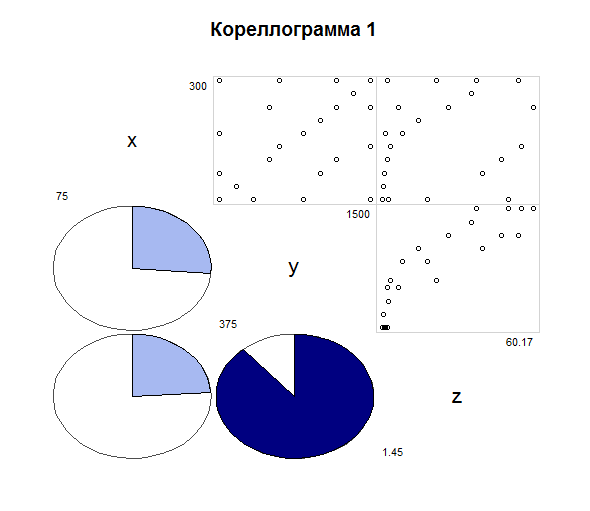
> # Инициализация данных
> x <- c(75, 75, 75, 75, 100, 125, 125, 150, 150, 175, 175, 200, 200, 225, 250, 250, 250, 275, 300, 300, 300, 300)
> y <- c(375, 625, 1000, 1500, 500, 375, 1125, 750, 1250, 825, 1500, 375, 1000, 1125, 750, 1250, 1500, 1375, 375, 825, 1500, 1250)
> z <- c(1.452, 3.705, 18.857, 50.434, 1.956, 2.272, 40.306, 3.368, 47.686, 4.464, 55.63, 2.611, 9.077, 15.304, 7.559, 27.257, 60.174, 35.965, 3.355, 22.491, 38.036, 54.237)
> myData<-data.frame(x,y,z)
> myData$lnZ<-log(myData$z)
>
> # Собственно, вывод корреляционной матрицы
> cor(myData[,c("x","y","z")])
x y z
x 1.0000000 0.2625290 0.2394832
y 0.2625290 1.0000000 0.8857714
z 0.2394832 0.8857714 1.0000000
Обратите внимание, мы взяли не 4 столбца таблицы, а только три. Столбец lnZ опущен. Хотя данная матрица неплохо читается, её можно сделать более удобной для восприятия с помощью функции symnum, заменяющей числовые значения на символы.
Код:
> symnum(cor(myData[,c("x","y","z")]))
x y z
x 1
y 1
z + 1
attr(,"legend")
[1] 0 ‘ ’ 0.3 ‘.’ 0.6 ‘,’ 0.8 ‘+’ 0.9 ‘*’ 0.95 ‘B’ 1
Для сравнения
Код:
> symnum(cor(myData[,c("x","y","lnZ")]))
x y l
x 1
y 1
lnZ . * 1
attr(,"legend")
[1] 0 ‘ ’ 0.3 ‘.’ 0.6 ‘,’ 0.8 ‘+’ 0.9 ‘*’ 0.95 ‘B’ 1
Однако, есть и другой способ сделать это, да и к тому же красиво, нарисовав коррелограмму. Такой рисунок несказанно обогатит статью и поразит всех читателей. Для этого нужна установленная библиотека corrgram.
Примеры вызовов функции приведены ниже.
Существует 4 возможных отображения корреляции:
panel.pts -- диаграмма разброса
panel.pie -- круговая диаграмма, меняет цвет и заполненность в зависимость от коэффициента корреляции (отрицательная -- красная, положительная -- синяя).
panel.ellipse -- рисует красоту, как показана на рисунке 3. В общем, границы и аппроксимацию.
panel.shade -- закрашивает прямоугольник в зависимости от коэффициента корреляции.
Их присваивают, соответственно lower.panel или upper.panel, в зависимости от того, где нужен рисунок: сверху или снизу.
Также можно выводить название переменных и минимум/максимум значений, как это показано ниже.
Код:
>
> library(corrgram)
>
>
> corrgram(myData[,c("x","y","z")], lower.panel=panel.pie,
+ upper.panel=panel.pts, text.panel=panel.txt,
+ diag.panel=panel.minmax, main="Кореллограмма 1")
>
Код:
> corrgram(myData[,c("x","y","lnZ")], lower.panel=panel.pts,
+ upper.panel=panel.pie, text.panel=panel.txt,
+ diag.panel=panel.minmax, main="Кореллограмма 2")
>

Код:
> corrgram(log(myData[,c("x","y","z")]), order=TRUE, lower.panel=panel.shade,
+ upper.panel=panel.ellipse, text.panel=panel.txt,
+ main="Кореллограмма 3\n Логарифмы величин")
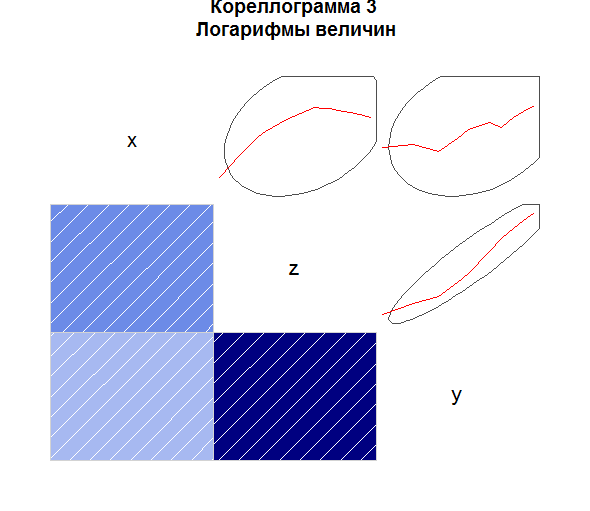
Понятно, что на трех переменных это не сильно показательно, но если их будет десяток, то картинка будет гораздо симпатичнее.